
.jpg?width=1700&height=900&name=api-intro-bg%20(1).jpg)
Hollywood-quality AI voices.
Ethically sourced. Streamed in an instant.
Real-time text-to-speech for voice applications from the team that created AI voices for Oscar-winning movies.
Used by industry
leaders
leaders







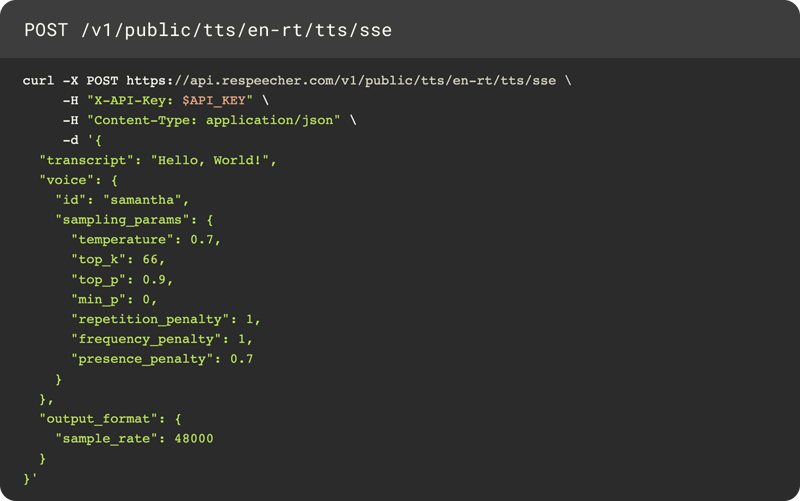
Clean, fast, scalable API
Instantly transform text into lifelike audio streams with our Real-time TTS API. Perfect for creating interactive, dynamic experiences across any industry. Explore our API documentation to learn more.
Flexible Pricing
Pay As You Go
- No subscriptions
- Cancel anytime
- Top up or enable auto-recharge to never run out
$2
/ hour*
All voices currently $2 per 60,000 characters or roughly $2 per hour.
Need customized voices?
Need more hours or deeper voice customization? Talk to us if your project needs flexibility, advanced features, and high-volume usage.
Custom pricing based on usage volume
.jpg?width=1700&height=900&name=api-intro-bg%20(2).jpg)